
이번 포스팅에서는 Set에 대해 알아보자.
Set ?
*Set : 세트, 집합 등
특정한 값을 저장하는 자료 구조 중 하나다.
Set을 이야기할 때는 자연스레 List 자료 구조와 비교하게 된다.
List : 데이터를 저장하는 순서가 정해져 있으며, 중복된 값을 저장할 수 있다.
Set : 데이터를 저장하는 순서가 없으며, 중복된 값을 저장할 수 없다.
위 내용만 보아도, 확실히 두 자료 구조는 반대의 성격을 띄고 있다고 볼 수 있다.
Set 자체는 인터페이스로 제공되며, 다음과 같은 종류의 클래스로 구현할 수 있다.
● HashSet
Set의 대표 클래스라 할 수 있다.
위에서 설명한 대로, 데이터를 중복 저장할 수 없고 저장 순서도 없다.
● TreeSet
데이터가 오름 차순으로 정렬되어 저장된다.
● LinkedHashSet
데이터가 입력된 순서대로 저장된다.
TreeSet과 LinkedHashSet의 특징을 보면,
HashSet의 정렬이 없다는 단점을 보완한 클래스라 볼 수 있다.
그리고 위 두 클래스는 HashSet을 상속하는 구조를 띈다.
예제
✅ HashSet
Set을 대표하는 클래스인 만큼, HashSet으로 기본 사용법을 알아보자.
🟢 Set 중복 허용 여부 확인 & Set 사이즈 확인
Set<String> set = new HashSet<>();
set.add("Oscar");
set.add("Oscar");
set.add("Taron");
set.add("Human");
System.out.println("set 사이즈 : " + set.size());
Set에 4개의 데이터를 추가해주고, 사이즈를 출력했다.
결과)

중복된 값은 저장하지 않기에, 3개가 출력된 모습이다.
🟢 Set이 보유한 데이터 출력
Set의 데이터를 확인하기 위해서는 Iterator라는 반복기를 사용해야 한다.
Set 인터페이스에서 iterator() 메서드를 지원한다.
Iterator는 hasNext() 메서드로 다음 값의 존재 여부를 판단할 수 있고,
next() 메서드로 다음 값을 불러온다.
데이터 저장 순서가 보장되지 않기에, 어떤 값을 불러올지는 모른다.
Set<String> set = new HashSet<>();
set.add("Oscar");
set.add("Stella");
set.add("Taron");
set.add("Human");
set.add("Naki");
set.add("Harry");
set.add("Sam");
set.add("Lion");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
Set에 8개의 데이터를 넣고 출력했다.
결과)
예상대로, 위에서 입력한 순서대로 출력이 되지 않는 모습이다.
✅ TreeSet
위 HashSet 예제와 동일한 구조에서 HashSet → TreeSet으로 변경했다.
Set<String> set = new TreeSet<>();
...
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
결과)
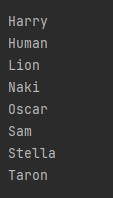
오름차순으로 데이터가 정렬되어 출력된 모습이다.
✅ LinkedHashSet
이번에도 마찬가지로, 동일한 구조에서 TreeSet → LinkedHashSet으로 변경했다.
Set<String> set = new LinkedHashSet<>();
...
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
결과)
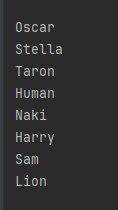
입력한 순서대로 데이터가 정렬되어 출력되었다.
보다시피 TreeSet이나 LinkedHashSet을 사용하면 데이터 정렬은 어느정도 손볼 수 있다.
결국, List와 명확한 차이점은 데이터의 중복 허용 여부라고 할 수 있다.
Set vs List 런타임 속도 비교
각각의 명확한 특징은 더 이상 말할 것도 없고,
런타임 시간을 비교하며 특징을 확인해 보겠다.
동일한 작업을 List와 Set으로 구분하여 진행한다.
✅ 프로세스
1. 각 자료 구조에 데이터를 추가하기 전 시스템 시간을 찍어본다.
2. 각 자료 구조에 100,000개의 데이터를 추가한다.
3. 데이터가 추가된 후 시스템 시간을 찍어 시간을 비교한다.
4. 각 자료 구조에 임의의 값을 탐색하는 함수를 사용해본다.
5. 시스템 시간을 찍어 탐색하는데 소비한 시간을 비교한다.
/* Set 자료 구조 테스트 */
Set<Integer> set = new HashSet<>();
// 반복문 돌리기 전 시스템 시간 출력
System.out.println("Set - 반복문 돌리기 전 : " + System.currentTimeMillis());
for (int i = 0; i < 100000; i++) {
set.add(i);
}
// 반복문 돌린 후 시스템 시간 출력
System.out.println("Set - 반복문 돌린 후 : " + System.currentTimeMillis());
// 임의 데이터 탐색
System.out.println(set.contains(85000));
// 데이터 탐색 후 시스템 시간 출력
System.out.println("Set - 데이터 검색 후 : " + System.currentTimeMillis());
/* List 자료 구조 테스트 */
List<Integer> list = new ArrayList<>();
// 반복문 돌리기 전 시스템 시간 출력
System.out.println("List - 반복문 돌리기 전 : " + System.currentTimeMillis());
for (int i = 0; i < 100000; i++) {
list.add(i);
}
// 반복문 돌린 후 시스템 시간 출력
System.out.println("List - 반복문 돌린 후 : " + System.currentTimeMillis());
// 임의 데이터 탐색
System.out.println(list.contains(85000));
// 데이터 탐색 후 시스템 시간 출력
System.out.println("List - 데이터 검색 후 : " + System.currentTimeMillis());
결과는 다음과 같다.
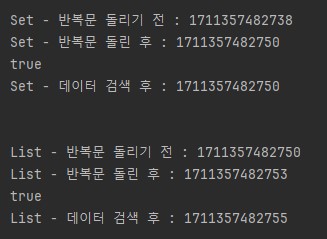
✅ 결과 비교
● 반복문을 돌리며 데이터가 추가 되는 시간
Set : 12ms
List : 3ms
List 자료 구조가 약 4배 빨랐다.
이는 순서대로 저장하는지에 대한 여부 차이라 볼 수 있다.
Set 자료 구조의 경우 어디에 저장할 지에 대한 명확한 기준이 없기 때문이다.
● 데이터 탐색에 걸린 시간
Set : 0ms
List : 2ms
Set 자료 구조가 최대 2배 이상 빨랐다고 볼 수 있다.
List의 경우, 0번 인덱스부터 순서대로 값을 찾다보니
최후방 인덱스의 값을 탐색하려면 오래걸릴 수 밖에 없는 것이다.
반면 Set의 경우, 순서를 보장하지 않는 만큼 최후방 인덱스의 값을 탐색해도
빠른 시간내에 찾아오는 결과를 확인할 수 있다.
속도적인 면에서 각 자료 구조가 어떤 상황에서 유리하게 작용할 지 이해했다.
이러한 상황에 더해 중복 값을 허용할 것인지에 대한 여부, 관리 순서에 대한 중요도 등까지 고려한다면
각 상황에 맞는 자료 구조를 선택하는 것이 좋다고 생각한다.
이번 포스팅에서는 Set 자료 구조에 대해 알아보았다.
유용하게 사용해볼 수 있을 것 같다.

'Java (자바)' 카테고리의 다른 글
| [Java] 데이터 직렬화 / Serializable (0) | 2024.03.30 |
|---|---|
| [Java] Pair / 자료 구조 / 2개의 데이터 관리하기 (0) | 2024.03.25 |
| [Java] Garbage Collector (0) | 2024.03.06 |
| [Java] JVM 메모리 할당 방식 - Stack · Heap Memory (2) | 2024.03.05 |
| [Java] JDK · JRE · JVM (1) | 2024.03.04 |